Scalable High-Performance Architecture for Convolutional Ternary Neural Networks on FPGA
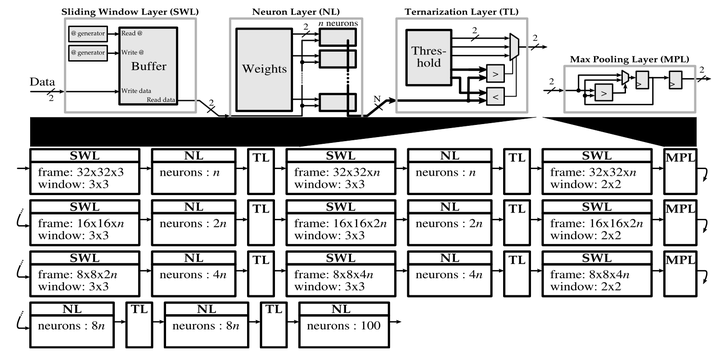 CNN architecture overview
CNN architecture overview
Abstract
Thanks to their excellent performances on typical artificial intelligence problems, deep neural networks have drawn a lot of interest lately. However, this comes at the cost of large computational needs and high power consumption. Benefiting from high precision at acceptable hardware cost on these difficult problems is a challenge. To address it, we advocate the use of ternary neural networks (TNN) that, when properly trained, can reach results close to the state of the art using floating- point arithmetic. We present a highly versatile FPGA friendly architecture for TNN in which we can vary both the number of bits of the input data and the level of parallelism at synthesis time, allowing to trade throughput for hardware resources and power consumption. To demonstrate the efficiency of our proposal, we implement high-complexity convolutional neural networks on the Xilinx Virtex-7 VC709 FPGA board. While reaching a better accuracy than comparable designs, we can target either high throughput or low power. We measure a throughput up to 27000fps at ≈7W or up to 8.36 TMAC/s at ≈13W.